如有疏漏或错误之处,请联系lytyuan@126.com,以便修改及完善,多谢支持!
感谢范新妍同学的帮助!
一、关于分式计算的简要说明
main.r是一个R程序,i每取一个不同值时,main独立运行一次,得到你想要的结果。
main.r代码如下:
#===============================
#your simulation code here
filename=paste(i,".csv",sep="")
write.csv(,filename)
#===============================
如果你想执行main.r 100次,你可以使用以下语句
for(i in 1:100){
source("main.r")
}
上述100次运算将顺序执行,如果main.r运算一次要50分钟,那么100次要5000分钟。
为了节省时间,你可能手动启动多个R进程(如RGui或RScript),甚至是登录到其他节点,再多启动几个R进程,然后把这100次计算任务手动分配给这些R进程。
更容易、更节省时间的方法是:你可以使用创建为分布式作业(Distributed Job),并通过Windows HPC Server Scheduler自动调度到其他计算节点运行。
如果HPC为你自动启动了100个R进程,同时为你计算,那么总计算时间将是5000/100=50分钟。当然实际运行时间可能更长些,有两个原因:(1)main.r可能在一些负载较重的节点运行,每次运行时间可能会超过50分钟。(2)100个R进程可能没有一次性同时开启,需要排队,因为其他用户也可能占用了HPC资源,HPC Pack会根据实际情况进行调度。
二、使用方法
(一)对main.r进行改写
为了进行分布式计算,main.r改写如下
#===============================
Args < - commandargs()
i < - args[6]
i < - as.numeric(i)
#your simulation code here
#程序中不要使用任何并行包,如parallel
#请务必将结果输出到磁盘上,每次输出结果的文件名不能一样
filename=paste(i,".csv",sep="")
write.csv(,filename)
#===============================
main.r和所需的其他程序及数据文件,请保存在R的当前工作目录(通常是Z:\User\Documents或Z:\User\Documents\R)。
(二)测试main.r是否可以正确运行
进入Window的“命令提示符”窗口
进入main.r所在目录,输入cd Z:\User\Documents\R,并回车
再输入 "C:\Program Files\R\R-4.0.3\bin\x64\Rscript.exe" main.r 10,并回车,该命令将给出当i=10时的main.r的计算结果。

观察是否正确执行,是否输出了正确的结果。测试正确后进入下一步。
(三)创建分布式作业
1. 打开Job Manager
在桌面上双击“HPC Job Manager”图标,打开HPC Pack 2016作业管理器。
2. 新建参数扫描作业(Parametric Sweep Job)
在窗口右侧单击“新建参数扫描作业”(New Parametric Sweep Job)
3. 作业属性设置
作业模板(Job template):Core(可用的模板名称,请联系管理员!)
起始值(Start value):1
最终值(End value):100
增量值(Increment value):1
命令行(Command line):"C:\Program Files\R\R-4.0.3\bin\x64\Rscript.exe" main.r *
工作目录(Working directory):\\UFS\HPCUserFile$\\User\Documents
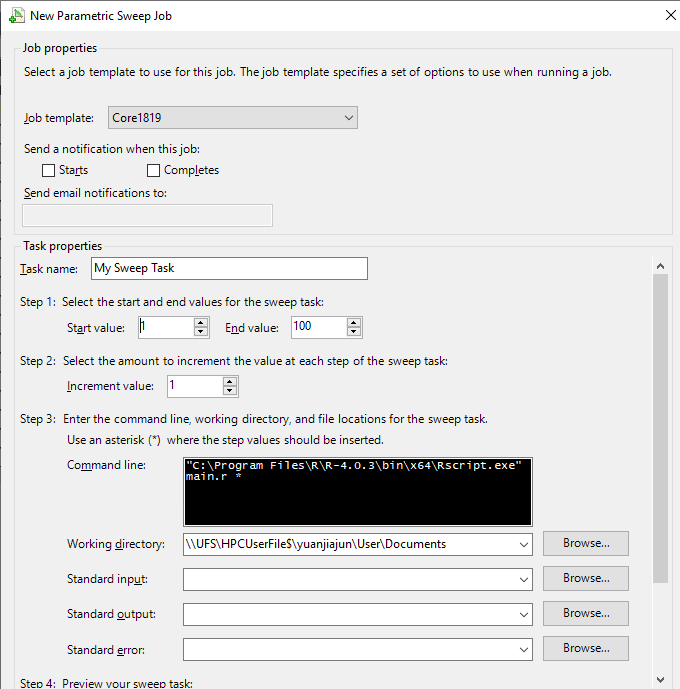
在Step 4: Preview your sweep task中会看到任务的命令行。
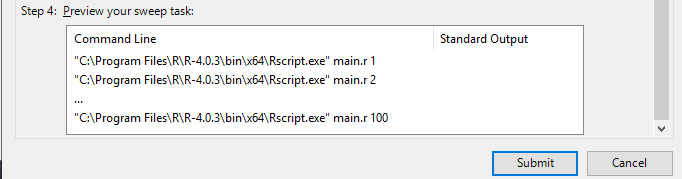
4. 最后选择提交(Submit),将创建100个任务,并开始计算。
提交后,可以作业管理器中查看作业运行状态、所分配的资源、错误输出等信息。
*注意:请务必先测试分布程序是否能得到正确的结果,比如可以先创建5个任务。
三、注意事项
1. 请务必使用网络路径
作业属性的“工作目录”,必须指定为main.r和所需的其他程序及数据文件所在的目录,而且必须是网络路径。
本例中,main.r和所需数据文件放在:
Z:\User\Documents\R
其网络路径是:
\\UFS\HPCUserFile$\\User\Documents\R
该路径即是作业属性的“工作目录”。
即“Z:\”的网络路径是“\\UFS\HPCUserFile$\\”,其中“”换成你自己的用户名,不用加“sehpc\”。
如果需要在main.r中将结果输出到工作目录之外的路径,比如输出到“Z:\”,则可以将
filename=paste(i,".csv",sep="")
改成
filename=paste("../../",i,".csv",sep="")
或改成
filename=paste("//UFS/HPCUserFile$//",i,".csv",sep="")
2. 结果务必输出到磁盘上,每次输出结果的文件名不能一样
进行分布计算时,结果不会输出到一个图形化窗口(如R Console),请务必将结果写入到工作目录(或Z盘其他目录)。
注意main.r将进行100次计算,每次计算都会输出一个结果文件,因为是放在同一个路径下,所以保存结果的文件名不能一样。
3. 关于R包的加载
在多节点分布计算时,安装到用户个人目录(通常是Z:/User/Documents/R/win-library/4.X)中的程序包将无法加载。因此,请联系管理员在系统默认的library目录安装所需的程序包。
4. 建议每次最多建立100个任务,以避免占用过多资源,影响其他用户!如有特殊需求,请联系管理员!
5. R程序中请勿使用任何并行包,如parallel。




