main.py是Python主程序,比如是一个统计模拟程序,需要执行很多次,可以通过HPC Pack提交到服务器集群运行。
一、main.py示例
为了进行分布式计算,main.py大致如下
#===============================
import sys
#读取参数,可用于区别输出结果的文件名
i = sys.argv[1]
#输出路径,输出到当前路径(HPC Pack提交作业时指定的working directory)
path = sys.path[0]
#打开输出结果的文件
file_handle = open(path +"/out" + str(i) +".txt", "w")
#your simulation code here
#程序中不要使用任何并行包
#以下假定输出sys.path
for line in sys.path:
file_handle.write(line+'\n')
file_handle.close()
#===============================
main.py和所需的数据文件,请存放在Z盘,以下假设在Z:\DjobTest目录。
二、测试main.py是否可以正确运行
进入Windows的“命令提示符”窗口(注意请勿双击桌面上的Anaconda Prompt图标进入)
进入main.py所在目录,输入cd Z:\DJobTest,并回车
再输入C:\ProgramData\Anaconda3\python.exe main.py 10,并回车,该命令将给出当i=10时的main.py的计算结果。
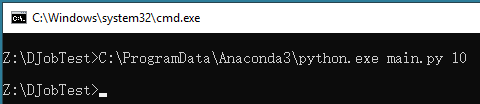
该示例程序会在Z:\DjobTest目录输出一个out10.txt。观察是否正确执行,是否输出了正确的结果。测试正确后进入下一步。如果提示出现mkl-service package failed to import的错误,请参见本文后面的解决方案。
注意:在测试时,请减少程序计算量,以方便快速出结果,节省测试时间。
三、分布式作业的建立及注意事项
(一)创建用于测试的分布作业
1. 打开Job Manager
鼠标点击Start -> Microsoft HPC Pack 2019 -> HPC Job Manager,找开HPC 2019作业管理器。
2. 新建参数扫描作业(Parametric Sweep Job)
在窗口右侧单击“新建参数扫描作业”(New Parametric Sweep Job)
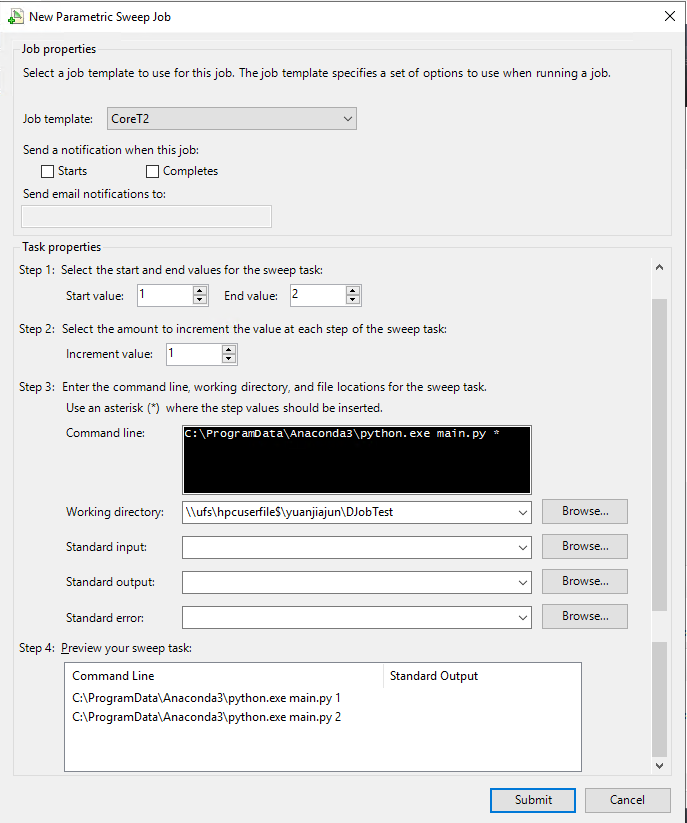
3. 作业属性设置
作业模板(Job template):Core(可用的模板名称,请联系管理员!)
起始值(Start value):1
最终值(End value):2
增量值(Increment value):1
命令行(Command line):C:\ProgramData\Anaconda3\python.exe main.py *
工作目录(Working directory):\\ufs\<sharename>$\<username>\DJobTest
其中,\\ufs\<sharename>$\<username>可以通过print(os.getenv("HOMESHARE"))获得,也可以直接在cmd窗口输入命令set,然后查看HOMESHARE的值。
4. 最后选择提交(Submit),将创建2个测试任务,并开始计算。
提交后,可以在HPC Pack 2019 Job Manager中查看作业运行状态、所分配的资源、错误输出等信息。
注意:测试分布程序时,请务必创建少量任务。测试通过后可正式提交分布运算任务,最好不要超过100个任务。
(二)注意事项
1. 请务必使用网络路径
作业属性的“工作目录”,必须指定为main.py和所需数据文件所在的目录,而且必须是网络路径,也就是要把“Z:”改成UNC路径,可以通过print(os.getenv("HOMESHARE"))获得,也可以直接在cmd窗口输入命令set,然后查看HOMESHARE的值。
2. 结果务必输出到磁盘上
进行分布计算时,请务必将结果写入到工作目录(或Z盘其他目录)。
3. 建议每次最多建立100个任务,否则建立任务的时间可能会大大超过任务计算的时间!
4. Python程序中请勿使用任何并行包。
四、关于加载安装在USER_SITE目录的Python包
用户可能会通过pip install --user命令,将包安装到USER_SITE目录,在提交并行作业时,如果想加载该目录下的包,需要通过以下语句将USER_SITE目录加入到搜索路径中
import sys,os,site
mypath=site.getusersitepackages()
mypath=mypath.replace('Z:',os.getenv('HOMESHARE'))
sys.path.append(mypath)
五、关于使用自己建立的Python环境
上述示例中使用的是Anaconda的base环境(C:\ProgramData\Anaconda3\python.exe)。有的时候你可能需要使用自己建立的python环境,方法如下:
(一)建立Python环境
1. 双击桌面上的Anaconda Prompt
2. 建立虚拟环境并激活
conda create -n <环境名称>,比如conda create -n mypython
conda activate <环境名称>,比如conda activate mypython
3. 安装你所需的包
用conda install安装,如conda install geopandas
以上会自动安装python
如果想要安装指定版本的python,请在安装其他包之前,先安装python
conda install python=3.8.8(指定某个python版本)
然后再安装其他包
上述安装好的环境保存在“Z:\User\Documents\Python\Conda\envs\<环境名称>”目录。
(二)HPC Pack中使用自建的Python环境
在新建参数扫描作业(Parametric Sweep Job)后,命令行(Command line)由“C:\ProgramData\Anaconda3\python.exe main.py *”改成
\\ufs\<sharename>$\<usernaem>\User\Documents\Python\Conda\envs\<环境名称>\python.exe mymain.py *
注意其中的“\\ufs\<sharename>$\<usernaem>”就是“Z:”的网络路径,可以通过print(os.getenv("HOMESHARE"))获得,也可以直接在cmd窗口输入命令set,然后查看HOMESHARE的值。




